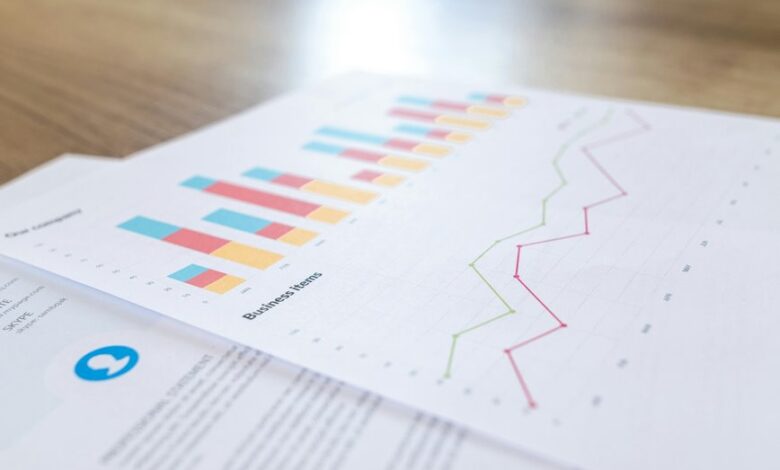
The monitoring summary for 111.90.150.204p consolidates throughput, latency variance, and uptime into a concise narrative. Reports emphasize stable performance with occasional jitter and peak load events, translated into prioritized alerts and visuals. The approach aligns governance and security constraints while offering actionable thresholds and benchmarking. It remains focused on repeatable workflows and scalable dashboards, inviting scrutiny of how these elements drive responder actions. A closer look reveals where a robust monitoring posture may still be needed.
What the Monitoring Summary Reveals for 111.90.150.204p
The monitoring summary for 111.90.150.204p presents a concise assessment of network activity, performance metrics, and event timelines associated with the monitored endpoint.
It outlines Monitoring context, IP profiling, and latency anomalies, highlighting stable throughput alongside sporadic jitter.
Stakeholder translation clarifies implications for reliability, security, and potential mitigations, guiding freedom-minded decisions without excessive interpretation or dilution of technical specifics.

How to Read Key Metrics in Reports (Uptime, Latency, and Anomalies)
Readers can quickly gauge system health by focusing on three core metrics: uptime, latency, and anomalies.
The report distills uptime trends to indicate availability stability, while latency measures response time variance and peak loads.
Anomaly patterns highlight deviations from baseline behavior, signaling potential issues.
Clear interpretation relies on consistent thresholds, periodic reviews, and disciplined benchmarking for informed decision-making and freedom in response strategies.
Translating Insights Into Stakeholder Reports That Drive Action
Effective translation of insights into stakeholder reports requires translating raw metrics into actionable narratives, supported by concise visuals and explicit recommendations. The process emphasizes insight mapping to align data with decision points and alert prioritization to spotlight critical events.
Reports present concise context, rationale, and impact, enabling independent interpretation, timely actions, and measurable follow-up without overreliance on technical minutiae.
Practical Automation and Dashboard Design for Ongoing Monitoring
Practical automation and dashboard design for ongoing monitoring focuses on establishing repeatable, low-maintenance workflows that sustain timely visibility into key metrics. The approach emphasizes modular automation dashboards and resilient data pipelines, enabling rapid insight without manual bottlenecks. Effective alert workflows complement dashboards, guiding action through concise notifications. The design remains adaptable, scalable, and minimally invasive within broader governance and security constraints.
Conclusion
The monitoring summary for 111.90.150.204p presents an impeccably boring narrative: stable throughput, minor jitter, and uptime that never surprises—except when it does, via latency variance and peak loads that slip past thresholds with grace. Reports translate this drama into neatly prioritized alerts and visuals, perfectly tailored for governance constraints. In short, the insights are actionable, the dashboards scalable, and the drama—or lack thereof—carefully manufactured to avoid unsettling stakeholders. Ironically, security loves predictability.



